Tomaino, Cooke and Hoover used ChatGPT-4, Bing Copilot, and Google Gemini to execute an entire research project from initial idea to final manuscript. They documented what these systems accomplished and where they failed across six stages of academic work. This paper is a reflective, empirical probe into the limits of AI as a research collaborator. It offers a clear-eyed diagnosis of what’s currently possible, what’s still missing, and why the human researcher remains essential not just for quality, but for meaning.
TL;DR? AI can mimic scientific work convincingly while fundamentally misunderstanding what makes it meaningful.
Article: Tomaino, G., Cooke, A. D. J., & Hoover, J. (2025). AI and the advent of the cyborg behavioral scientist. Journal of Consumer Psychology, 35, 297–315. Available at SSRN.
Detailed notes
1. Purpose and setup
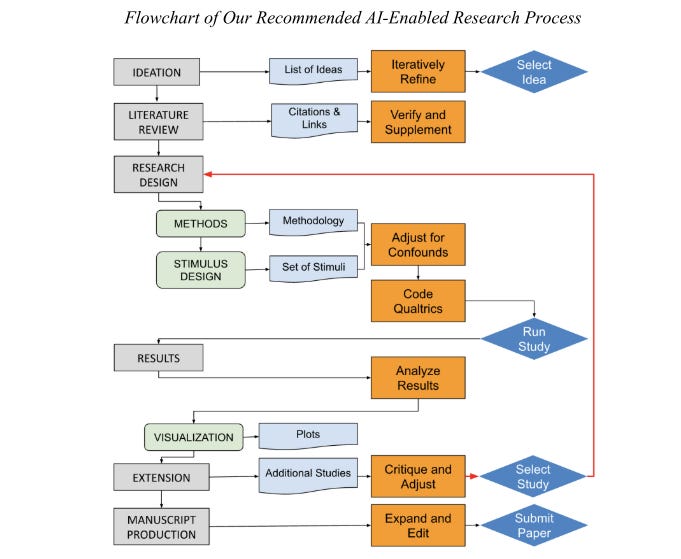
The paper sets out to examine whether Large Language Models (LLMs) can meaningfully perform the tasks involved in behavioural science research. Rather than speculate, the authors designed a practical test: conduct an entire behavioural research project using AI tools (ChatGPT-4, Bing Copilot, and Google Gemini) at every stage where possible. Their goal was to document what these systems can do, where they fall short, and what that tells us about the evolving relationship between AI and human thought in knowledge production. They call this process the “cyborg behavioural scientist” model where AI and human roles are blended, but with minimal human intervention wherever feasible.
They assessed AI performance across six canonical research stages:
Ideation
Literature Review
Research Design
Data Analysis
Extensions (e.g., follow-up studies)
Manuscript Writing
2. Ideation
The ideation phase tested whether LLMs could generate viable research questions. The authors used prompting sequences to elicit possible topics in consumer behaviour and asked the AIs to propose empirical research directions.
Findings:
AIs provided broad, somewhat vague suggestions (e.g. “Digital consumption and mental health”), which lacked the specificity required for testable hypotheses.
When asked to generate more focused ideas within a chosen theme (“ethical consumption”), the outputs improved. The researchers selected a concept called “ethical fatigue” - the idea that overexposure to ethical branding messages could dull their persuasive effect.
To get from general territory to a research-ready idea required multiple layers of human-guided refinement. The AI could not identify research gaps or develop theoretically sound rationales.
Conclusion: LLMs can function as brainstorming partners, surfacing domains of interest and initial directions, but they lack the epistemic grip to generate research questions that are original, tractable, and well-positioned within the literature.
3. Literature review
Once a topic was selected, the authors asked the AIs to identify relevant literature, assess novelty, and suggest theoretical foundations.
Findings:
The AIs failed to access or cite relevant academic literature. Most references were hallucinated, incorrect, or drawn from superficial sources.
The models often praised the research idea without offering critical evaluation or theoretical positioning.
The inability to access closed-access journals was a major barrier. Even when articles were available, the AIs rarely retrieved or interpreted them meaningfully.
Conclusion: AI cannot currently perform reliable literature reviews - its lack of access, weak interpretive depth, and tendency to hallucinate references make this stage unsuitable for unsupervised delegation.
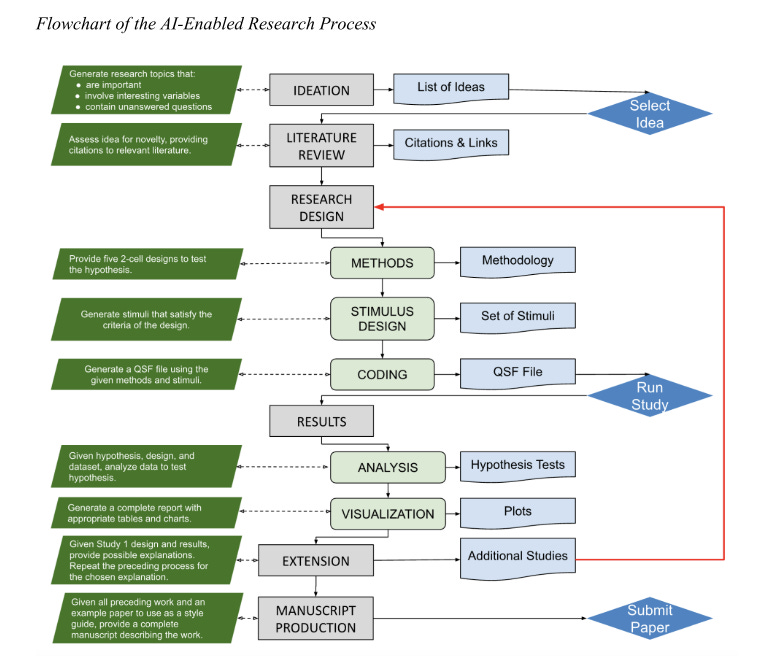
4. Research design
The AIs were tasked with designing an experiment to test the hypothesis that ethical branding becomes less effective when consumers are overexposed to it.
Findings:
The AI-generated designs were broadly plausible but flawed. Some included basic confounds (e.g. varying both message frequency and content type simultaneously).
With human corrections (e.g. balancing exposure conditions, clarifying manipulations), the designs became usable.
Stimuli generation (e.g. ethical vs. non-ethical brand statements) was one of the strongest areas for AI—responses were realistic, targeted, and ready for use.
The AIs failed to produce usable survey files in Qualtrics’ native format (QSF). ChatGPT attempted it, but the output didn’t meet schema requirements.
Conclusion: AI shows potential as a design assistant, especially for stimulus creation and generating structural ideas, but human researchers must ensure validity, feasibility, and proper implementation, so technical execution remains limited.
5. Data analysis
Here, the authors uploaded actual survey data and asked the AIs to perform statistical analysis.
Findings:
Gemini could not handle data uploads, so only ChatGPT and Bing were tested.
Both AIs recognised the appropriate statistical test (ANOVA), and produced plausible-looking outputs.
However, the reported statistics included errors, misinterpretations, and unverifiable results.
The AIs produced attractive data visualisations, but these are only useful if based on accurate analysis—which was not guaranteed.
Conclusion:
AIs are not yet reliable for statistical analysis in behavioural research - even when superficially competent, the risk of hidden errors is too high, and results need to be independently verified.
6. Extensions and follow-up studies
The authors asked the AIs to suggest follow-up studies to deepen the insight or test mechanisms.
Findings:
When prompted for mechanisms behind “ethical fatigue,” the AIs produced vague or re-descriptive explanations (e.g. cognitive overload, saturation).
Moderator suggestions (e.g. framing effects) were disconnected from theory and often lacked rationale.
The authors chose one AI-suggested study (testing gain vs. loss framing in ethical messages) and ran it, but it produced null results. The AI model was unable to explain the relevance of its own proposed manipulation.
Conclusion: AI struggles to generate meaningful theoretical extensions or mechanism tests - these require deeper reasoning and coherence than the models can currently provide.
7. Manuscript writing
The authors then tasked the AIs with writing the final manuscript, using the AI-generated ideas, designs, and results.
Findings:
The output was structurally coherent but conceptually weak. Writing quality was fluent, but content was shallow.
The methods and results sections were especially poor - often inaccurate or missing key details.
References were incomplete or invented, and one core citation was hallucinated.
Editing by the researchers would have been required to make the paper submission-ready, but they left the text untouched to reflect the AI’s raw capacity.
Conclusion: AIs can generate readable first drafts but cannot be trusted to produce publishable manuscripts. Their usefulness lies in formatting, framing, and copy generation but not intellectual synthesis.
8. Overall evaluation and performance summary
The authors provide a matrix evaluating AI performance across all stages:
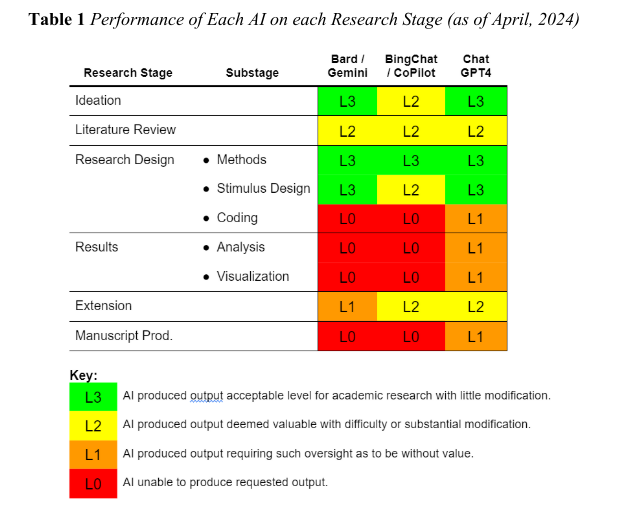
Their overall position is that AI models can support behavioural researchers but cannot replace them, because. LLMs act more like research assistants than collaborators or co-authors.
Broader implications:
Researchers should document AI use, including prompts and outputs, to maintain open science principles.
PhD students should be taught how to use AI critically—not as a shortcut, but as a tool that still requires judgment.
Reviewers should not use AI to evaluate manuscripts, due to the risk of introducing bias, superficial feedback, or flawed reasoning.
Journals should develop clear AI-use policies, especially regarding data analysis, citation practices, and manuscript drafting.
The paper ends by returning to a more existential question: not whether AI can perform the role of the behavioural scientist, but whether it should. Human researchers derive joy and meaning from shaping ideas, evaluating nuance, and building conceptual frameworks, so delegating this work to AI tools may improve efficiency, but it also risks displacing the very experience that makes research worthwhile. The future may involve choices about which parts of the process we want to automate and which we should consciously preserve as human.